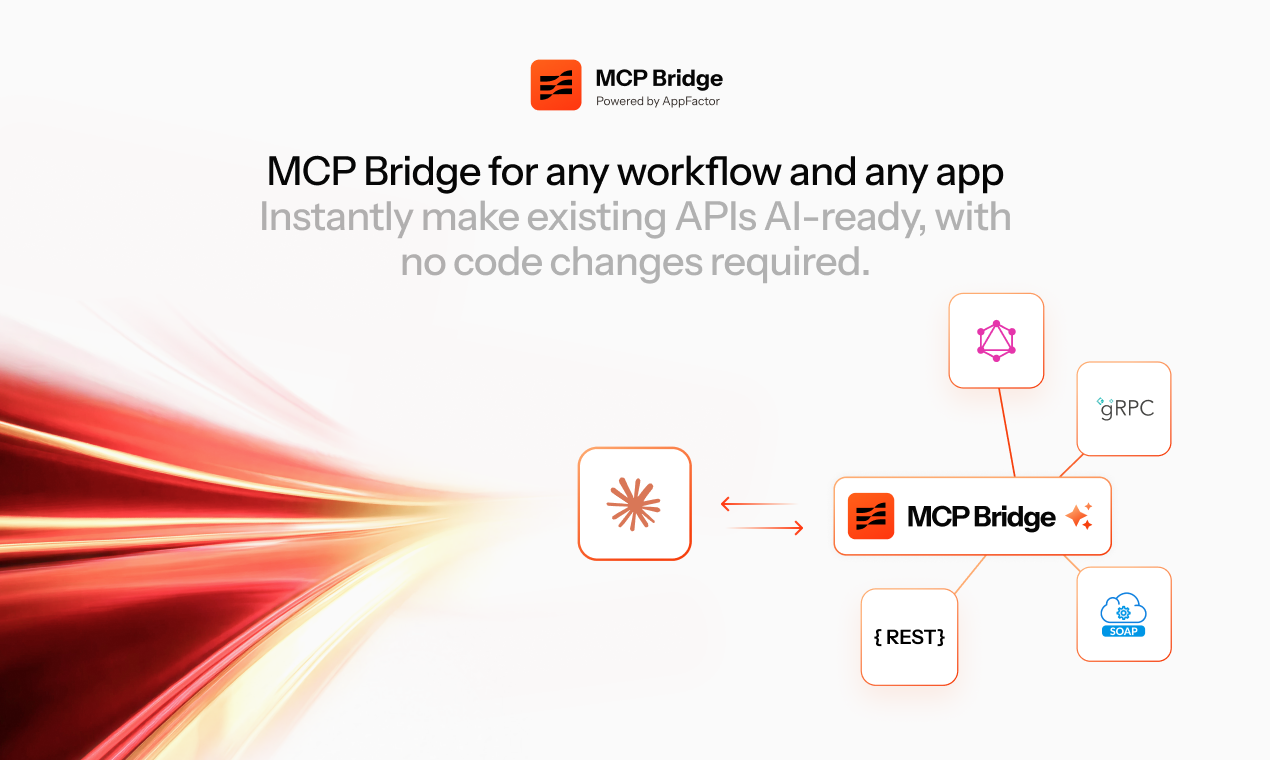
MCP Bridge Part 2: Code Mode - 3 meta-tools instead of 200 tool definitions
The average MCP tool definition costs about 250 tokens. Names, descriptions, parameter schemas, return types. It adds up faster than you'd think.
Now take an enterprise API. A reasonable REST surface has 60 operations. A GraphQL schema can have 200. A federated mesh? Forget it. At 250 tokens per definition, a 200-operation surface costs 50,000 tokens of context before the agent does any work. That's most of a typical context window. The agent has barely been introduced to the task and the prompt is already mostly schema.
We've been watching this problem grow as customers wire bigger and bigger API portfolios into their agents. It's the most predictable failure mode in production agentic systems: as the tool catalog grows, the agent gets dumber. Lost-in-the-middle is a real effect; so is schema dilution, where the model can't tell which of 80 lookup operations is the right one because they all read the same way. You can throw a bigger model at it, but that's a bandaid.
The pattern Cloudflare wrote about, that Anthropic explored independently, and that the open-source context-mode project implements, Code Mode, is the right answer. We've built it into MCP Bridge.
The three meta-tools
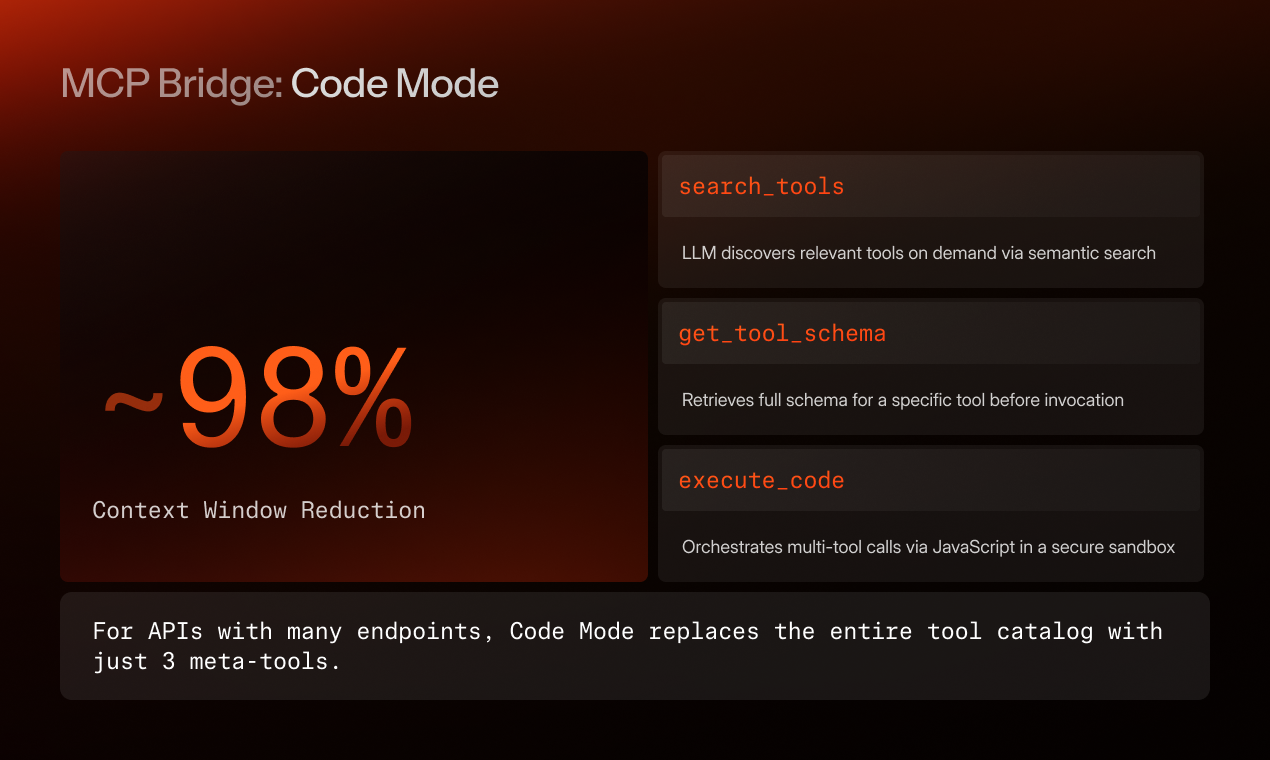
Instead of loading every tool definition into the prompt, the agent gets three:
1. search_tools(query): the agent describes what it needs in natural language. MCP Bridge runs a hybrid semantic + full-text search over the tool catalog and returns a short ranked list with names, one-line descriptions, and tool IDs. ~50–100 tokens of output.
2. get_tool_schema(tool_id): given a specific tool the agent has identified, MCP Bridge returns the full schema: parameters, types, return shape, behavioral annotations. The agent pulls this only for tools it intends to call.
3. execute_code(js_source): the agent writes JavaScript that orchestrates one or more tool calls inside a sandboxed V8 isolate. Loops, conditionals, intermediate transformations, conditional branches based on intermediate results, all of it executes server-side, and only the final return value flows back to the model.
The cost is three tool definitions in context instead of 200. Across the surfaces we benchmarked, that's ~98% context reduction at the catalog level.
A worked example
Suppose the agent is asked: "Find all customers in EMEA who haven't placed an order in 60 days and send their account managers a CSV."
In the traditional pattern, the agent sees the full catalog and has to remember which of 60 operations are relevant. It then issues sequential tool calls back through the model loop, paying tokens both ways for each.
In Code Mode, the conversation looks like this: the agent calls search_tools for "list customers by region with last order date", the platform returns three candidate tools (crm.customers.search, crm.orders.list, comms.email.send_with_attachment), the agent fetches the schema for each, then writes a small JavaScript function that searches EMEA customers, loops through them checking for recent orders, collects stale customers, and returns a count plus a CSV.
The execute_code call runs server-side. The loop, the conditional, and the CSV serialization never touch the model. Only the final summary, count and the CSV string, flows back through inference.
In a traditional tool-loop, that same task is one model call per customer-orders pair, plus a final composition call. With 800 EMEA customers, that's 801 inference round trips. With Code Mode, it's three: one to plan, one to write the code, one to interpret the result.
Benchmarks
We measured on our internal API surface (anonymized, 67 operations across REST and GraphQL):
Context tokens (catalog only): 16,800 → 320 (−98.1%)
Average task end-to-end tokens: 42,400 → 9,100 (−78.5%)
Average task inference round trips: 12.6 → 3.2 (−74.6%)
Tool-selection accuracy (hand-graded): 71% → 88% (+17pp)
Model: Claude Sonnet equivalent for both runs. Task suite: 40 representative agent tasks ranging from one-shot lookups to multi-step orchestrations. We're publishing the methodology and task list at mcp-bridge.com/docs/benchmarks, bring your own benchmark and we'll happily compare.
When you don't want Code Mode
Below ~12 operations, the full-catalog approach still works fine and saves you one indirection. MCP Bridge defaults Code Mode on for any API surface above that threshold. Below it, the agent gets the regular catalog.
A few caveats worth flagging:
The sandbox is V8, capability-scoped, 30s default timeout. Async is supported; the global fetch is not exposed.
The agent has to be capable of writing reasonable JavaScript. Most current frontier models are; some local models are not. Worth testing before flipping the switch in production.
Code Mode shifts cost from tokens to platform compute. The trade is dramatically in your favor at current pricing.
Try it
Docs and a worked example are at mcp-bridge.com/docs/code-mode. 14-day trial. We'd love your feedback, specially if you've implemented something similar and have a different take on the tradeoffs.